玩转 Obsidian 08:利用 Dataview 打造自动化 HomePage

在「玩转 Obsidian」系列的第一篇《玩转 Obsidian 01:打造知识循环利器》中就介绍过 Obsidian 是一款践行 Zettelkasten1 的笔记工具。在使用过程中通过「笔记优先法则2」将知识「碎片化」和「原子化」,并遵循「知识循环3」将知识「组合」后进行输出。
在践行 Zettelkasten 的过程初期,由于我们的笔记数量较少,线索也比较单一,所谓知识管理也没遇到太大问题。例如有的人在用笔记学建筑,有人在学编程,也有人在学法律。总之在使用笔记时是有「一条主线」贯穿始终,帮助我们整理和输出知识。但是当「笔记卡片」积累到一定程度,我们的知识「线索」变得比较杂之后,就会遇到一些问题:
- 各种笔记种「线索太多」容易遗忘正在做的事情,例如未完成的摘要、写一半的博客、定期整理的「闪念胶囊」等。
- 各种相关 Todo 散落在笔记中,记不清也找不全,导致许多任务无法完成或推进。
这两个问题就属于「整理线索」的范畴,当笔记达到一定数量时一定会遇到此问题。
一名读者在使用过程中也提出了类似问题:

在他的概述中,他希望能够在一个类似「目录」的页面中,对「知识」做一个「有机的整合」,方便查阅和管理。
要解决「整理线索」问题,最简单的办法就是手动维护一个「目录页面」我称之为「HomePage」,在其中将所有的笔记进行组合,并且定时更新,这样我们就能很清晰的看到各类事情的进展,例如我的 HomePage 如下:
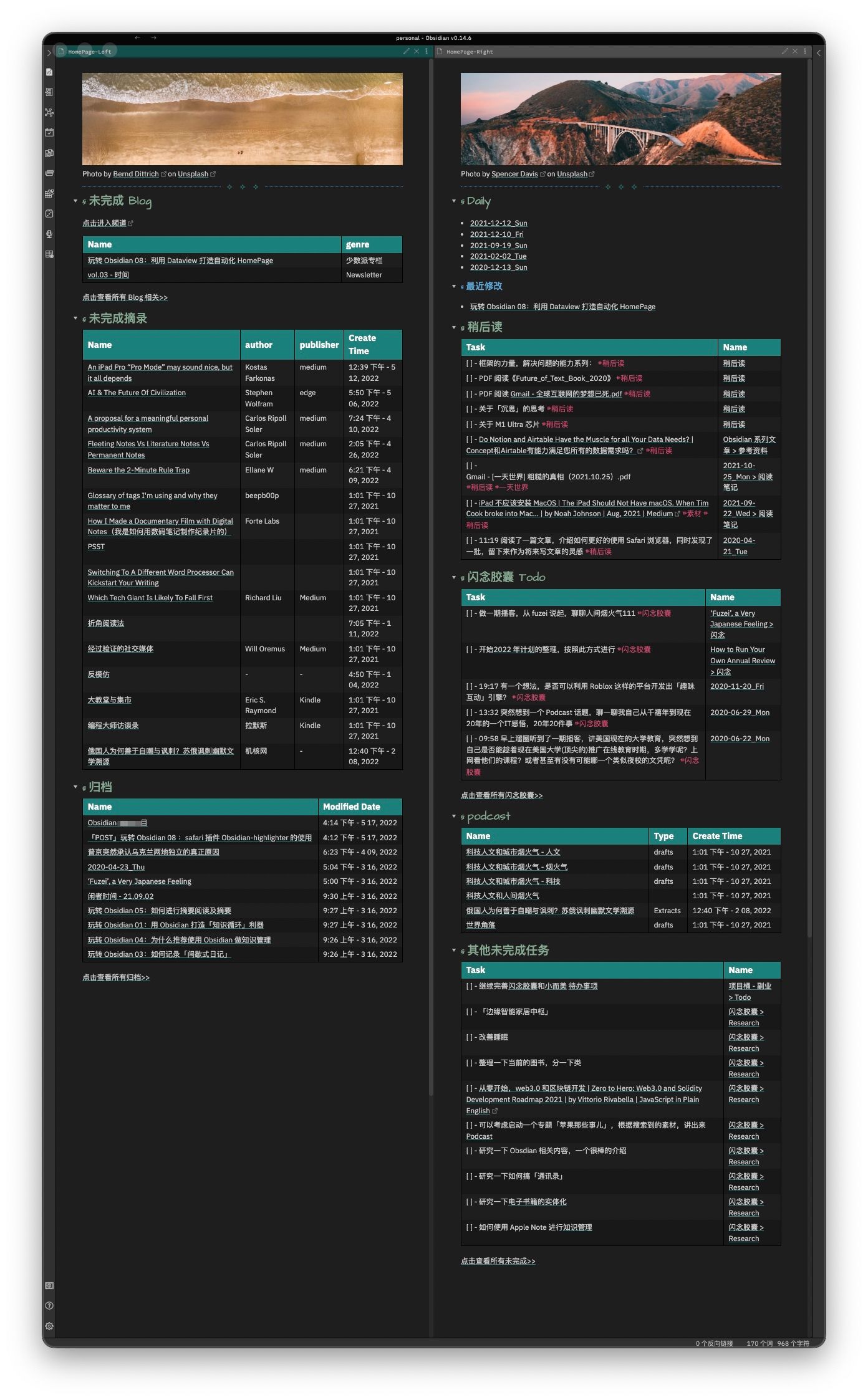
图中可以看到,这个 HomePage 页面包含以下线索:
- 进行中的Blog
- 未完成的摘录
- 未进行的稍后读
- 最新的「间歇式日记」
- 最近改过的文章
- ...
对于这个页面,其中的内容完全可以手动维护(根据自己的线索定期更新),前边提到的两个「线索过多」的问题就会迎刃而解。
但是既然使用了 Obsidian 这样一款「现代化笔记工具」,自然想到有没有什么「自动化」解决方案呢?答案是肯定的,今天就给大家介绍一下我的自动化解决方案:「利用 Dataview 打造自动化 HomePage」。
PS:预警,以下有大量代码描述,虽然已经做了足够细致的说明,但是对于没有耐心或一看代码就头痛的读者,我的建议是可以从这里放弃,以免难受。
打造自动化 HomePage
为了解决自动化「HomePage」这件事,在一番调研后,找到了一款 Obsidian 第三方插件 Dataview ,用它可以搭建出自动化「HomePage」,并且可以做到内容自动更新(解放双手,提高生产力)。
Dataview是一款 Obsidian 插件,它将 Obsidian 的「vault」(即文件仓库)当做数据库,并提供了基于 javascript API 以及 pipeline-based 的查询语法;通过编写「查询语句」将文件进行过滤、排序或从页面提取数据。
以上是「官方描述」,用一句话总结如下:
使用 Dataview 可以从 Obsidian 的文件库中查询内容(标题/正文/Todo)并可将内容应用于新的文件。
PS:Dataview 需要一些「编程知识」,大家如果没有基础也别太担心,只要仔细阅读跟上文章的节奏,并结合自己的用例替换我给出的「代码」中的「关键内容」即可。
例如,下边是一段代码,查询出所有包含 #Blog 的笔记:
dv.pages("#Blog");
如果你想查询所有包含 #Book 的笔记(阅读笔记)怎么办?很简单,将其中的 Blog 换成 Book 即可:
dv.pages("#Book");
安装&设置
直接在 Obsidian 的「第三方」插件市场中直接安装即可。安装完成之后,有三个选项需要打开,方便我们编写和执行「代码」:
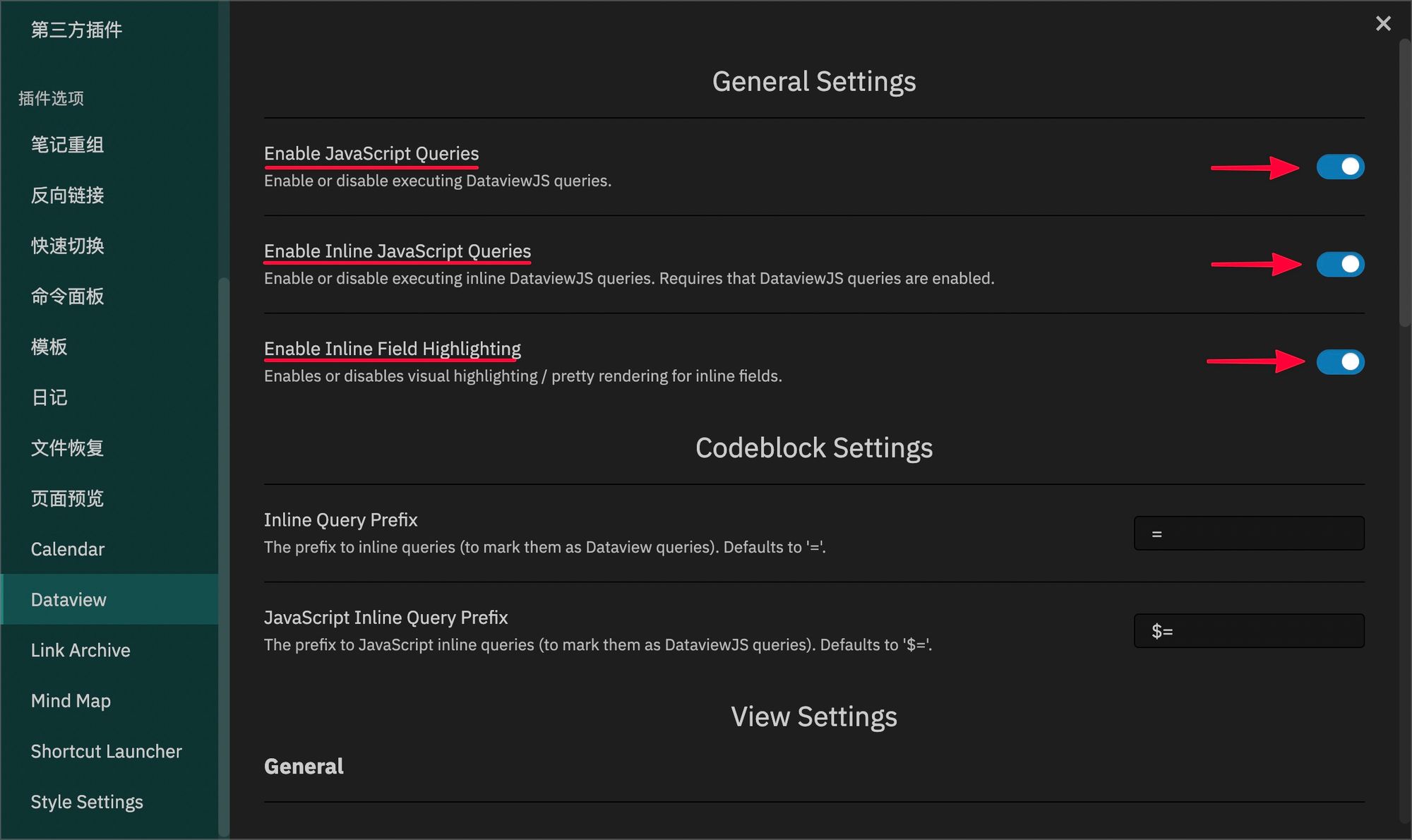
- Enable JavaScript Queries:启用或禁用执行 DataviewJS 代码进行查询。
- Enable Inline JavaScript Queries:启用或禁用执行内联DataviewJS查询。要求启用「Enable JavaScript Queries」。
- Enable Inline Field Highlighting:启用或禁用内联字段的视觉高亮显示以及渲染。
接下来我们一步步配置「自动化 HomePage」,下图是整个 HomePage 的完整代码,也可以点击查看 Github 上完整代码:
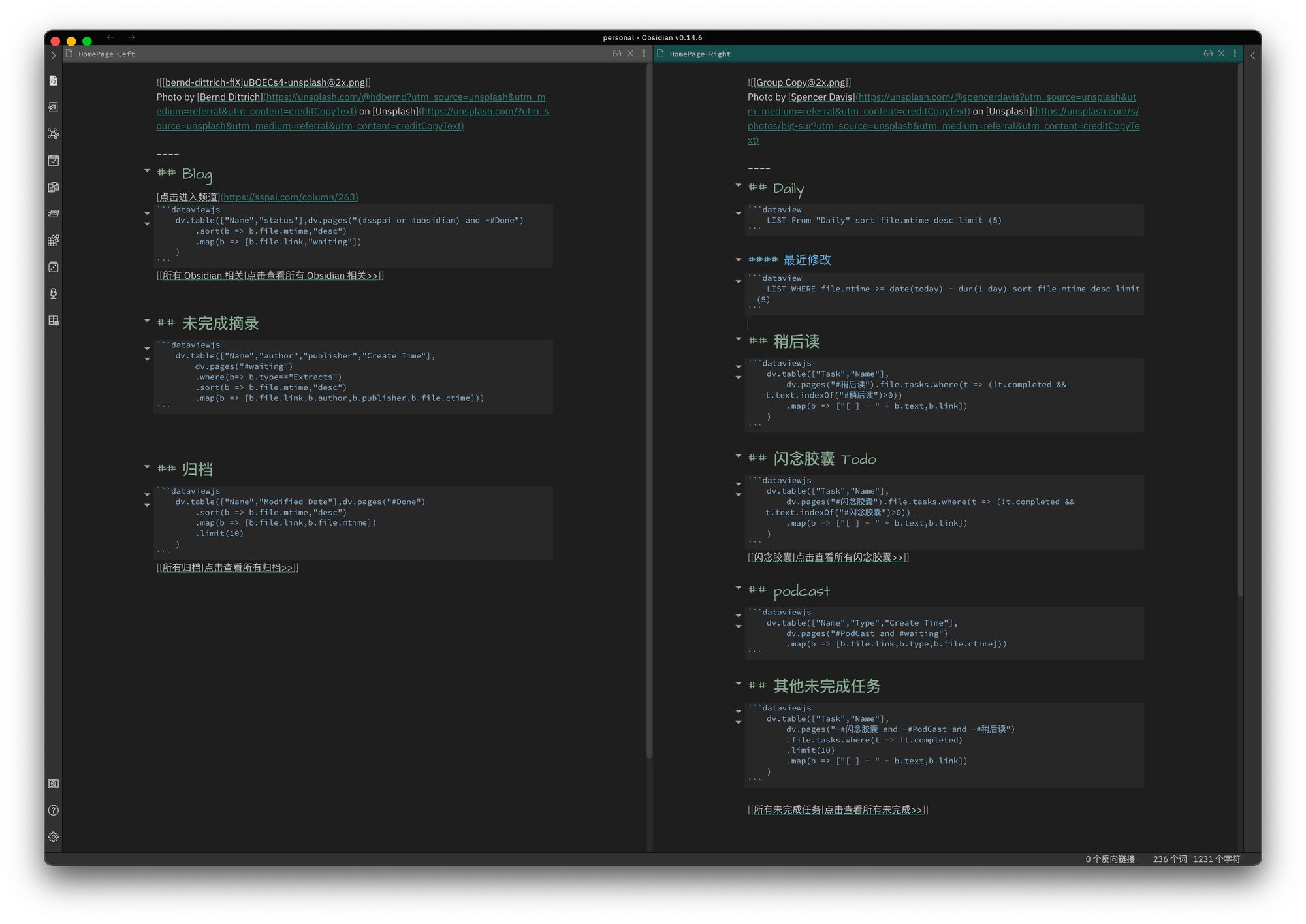
PS:如果您有一定的编程基础,可以去官方网站查询代码的使用教程。
上图中可以看到 HomePage 是由两个页面组成的:
- HomePage-Left
- HomePage-Right
HomePage 其实就是由多个符合 Dataview 的「代码块」组成,每个「代码块」会按照「条件」查询对应内容并呈现出来(表格或者列表)。
HomePage-Left
HomePage 左侧包含内容以下内容,接下来我们逐一拆解:
- 未完成的 Blog
- 未完成的摘录
- 所有归档
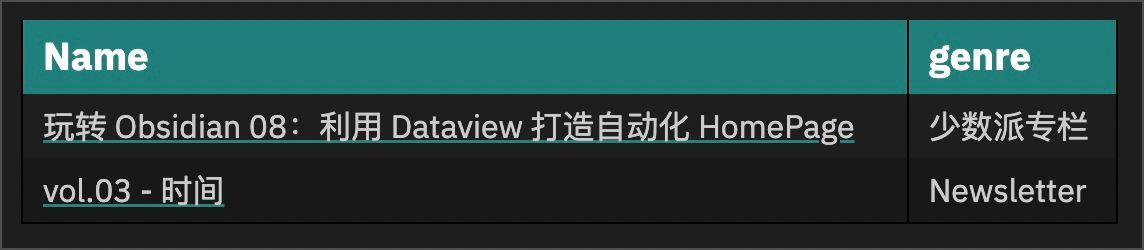
未完成的 Blog
在 Obsidian 中通过每一篇笔记设置 #Blog 标签标明它是一篇 Blog,如果文章完成编辑并发布了,再添加 #Done 标签即可。那么未完成的 Blog 指的是在所有笔记中筛选包含 #Blog 但不包含 #Done 的笔记,样式如下:
为了实现这个效果,其对应的完整代码:
关于代码有两点需要注意:
**第一点:**所有的代码都必须包含在如下代码块中才能够被执行(因为使用了 dataviewjs 语法,所以要注明语法类型 dataviewjs:

**第二点:**我们之所以可以用语法查询到相关笔记,是因为在「每篇笔记的开头」添加了「元数据」,例如一篇笔记的开头示例:

- tags: 可以设置笔记的「标签」,多个标签用逗号分割。
- genre: 标记文章的类型我用到的包括少数派专栏、Podcast、Newsletter。大家记住这个字段,后边会用到。
- Link:将来文章发布了,可以将链接补充到这里。
「元数据」中的字段是完全自定义的,除了上边介绍的三个,大家可以自己定义任何字段,例如一本书的「元数据」如下:
---
alias: "document"
last-reviewed: 2021-08-17
thoughts:
rating: 8
reviewable: false
---
延伸知识:标签嵌套
Obsidian 支持标签嵌套,例如标签Blog代表这篇笔记是一篇「博客」,标签Done代表这篇博客已经完成并且发布了。通常情况下我们给一篇「已经发表的博客笔记」设置两个标签Blog和Done,而嵌套标签就很简单,只需要设置Blog\Done这一个标签即可。
基于此,如果我们想要查询「所有未完成的 Blog」,那么查询语法应该是「所有标签为 Blog 但同时不包含 Blog\Done 的笔记」:

let:关键字,表示在其后要声明一个变量。pages:变量名,其值为「所有包含#Blog但是不包含#Blog\Done的笔记」,即未完成的 Blog。dv.pages:函数名,此函数将执行括号中的「查询语句」,查询结果为「符合语句的所有笔记数组」。"#Blog and -#Blog/Done":查询语句,可以按照and拆成两部分看。#Blog:左侧查询条件,即查询所有包含标签#Blog的笔记。and:「逻辑与」,代表查询条件同时满足左边#Blog和右边-#Blog\Done。-#Blog\Done:右侧查询条件,代表所有「不包含」标签#Blog\Done的笔记。注意-代表不包含。
所以代码含义为:「查询所有标签包含 #Blog 但同时不包含 #Blog\Done 的笔记」
延伸知识:dv.pages
dv.pages 是一个 JavaScript 函数,它的用法是查询「符合条件」的笔记,最终返回包含所有笔记的数组。
dv.pages 很明显是 JavaScript 语法,它的用法如下:
dv.pages()=> 「文件仓库」中所有笔记,以下默认都是在「文件仓库」中查询。dv.pages("#books")=> 所有标签是#books的笔记。dv.pages('"folder"')=> 所有在名为folder的文件夹下的笔记。dv.pages("#yes or -#no")=> 所有包含#yes但是不包含#no的笔记。dv.pages('"folder" or #tag')=> 所有在folder文件夹下的笔记「或者」标签包含#tag的笔记。
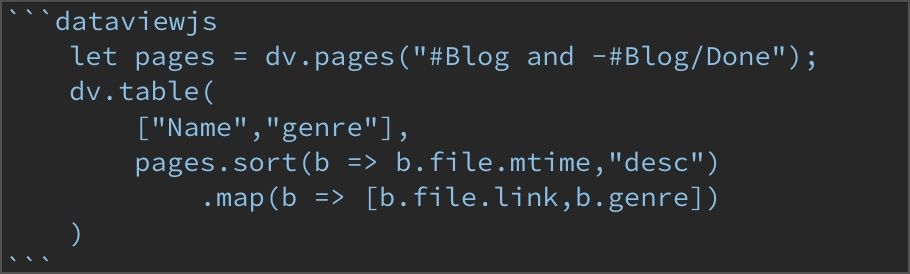
执行完语句后,变量 pages 包含了所有「未完成的 Blog 笔记」,接下来,我们希望用一个表格展示出所有「未完成的 Blog 笔记」。怎么将变量 pages 中的结果放入到表格呢?代码如下:

dv.table:函数名,此函数会在笔记中输出一张表格。["Name","genre"]:函数dv.table的第一个参数,指定了表格的两个字段,分别是笔记标题(双向链接的形式)和笔记类型(即前文中提到的「元数据」中的 'genre' 字段,忘记了可以返回去看一下)。pages.sort:函数名,即将变量pages(所有未完成的 Blog 笔记)中的笔记进行排序,排序规则在下文。b=>这里的b可以用任何字母代替,它有一些抽象,实际上b所指代的就是pages中的「每一篇笔记」。大家理解了这一点大家往下看就清晰了。b.file.mtime:指定使用「每一篇笔记」的file.mtime字段进行排序,b.file.mtime指的事笔记的「最后修改时间」。这里用到了dataview插件中的「隐式字段」下文有详细介绍。desc:指定「排序规则」为「倒排」或者「降序」。具体到当前就是指按照b.file.mtime「每篇笔记的最后修改时间」倒排,最新修改的笔记在表格最上边。.map:函数名,它等同于pages.sort(b=> b.file.mtime,"desc").map(),即对上一步「排序后」的所有笔记进行「重组」,只返回每篇笔记的「指定字段」(见下文)。b=>这里的b可以用任何字母代替,它依然代表pages中的「每一篇笔记」。其后的数组[b.file.link,b.genre]代表重组后的字段。b.file.link:它的意思是「指向笔记的链接」,即返回「排序后」的笔记中的每一个笔记的「双向链接」值(类似[[笔记1]])。它对应的就是表格中的第一个字段Name。b.genre:它的意思是笔记的「元数据」中的genre字段,即返回「排序后」的笔记中的每个笔记的「元数据」中genre字段的值,它对应的事表格中的第二个字段genre。- 综合看
.map(b=> [b.file.link,b.genre)就相当于pages.sort(b=> b.file.mtime,"desc").map(b=> [b.file.link,b.genre),其意思将「排序后」的笔记变量pages进行「重组输出」并与dv.table指定的两个字段对应,即返回笔记的「双向链接」和笔记「元数据」中的genre值。
延伸知识:隐式字段
Dataview 会自动向每个页面添加大量「元数据」,这些「元数据」就是「隐式字段」。即虽然在笔记中看不到它们,但它们确实一直在笔记的「元数据」中。点此查看详情。
以下为 Dataview 自动插入的「隐式字段」,我们在代码中都可以直接使用:
file.name:笔记的标题。file.folder:此文件所属文件夹的路径。file.path:完整文件路径(字符串)。file.link:指向文件的链接(链接)。file.size:文件的大小(字节)(数字)。file.ctime:创建文件的日期(日期+时间)。file.cday:创建文件的日期(只是一个日期)。file.mtime:上次修改文件的日期(日期+时间)。file.mday:上次修改文件的日期(只是一个日期)。file.tags:笔记中所有独特的标签的数组。副标签按级别细分,所以#Tag/1/A将以[#Tag, #Tag/1, #Tag/1/A]的形式存储在数组中。file.etags:笔记中所有显式标签的数组;与file.tags不同,不包括副标签。file.inlinks:包含当前笔记「双向链接」的其他笔记。file.outlinks:笔记中所有包含的双向链接、附件。file.aliases:当前笔记的所有「别名」,结果是数组形式。file.tasks:当前笔记所有「任务」组成的数组。例如- [ ] blah blah blah。
最后我们整体再看一下完整的语法:
它分为两部分:
- 第一部分:获取「所有标签为
#Blog但同时不包含#Blog\Done的笔记」,并赋值给变量pages。 - 第二部分:循环数组变量
pages,并输出「每一篇笔记」的「双向链接」和「元数据」中的genre字段值,组成一张表格。
PS:第一部分是介绍的最为细致,希望没有基础但是又很感兴趣的读者能够反复阅读了解其中含义(了解即可)。
未完成摘录
「未完成的摘录」展示样式如下:
在《玩转 Obsidian 06:如何用渐进式总结笔记,把知识交给未来的自己》中介绍了使用 Obsidian 摘录笔记的方法,对于摘录中的笔记我都会通过「元数据」进行组织,例如一篇摘录笔记的「元数据」如下:
---
author : "Kostas Farkonas"
link : "https://medium.com/geekculture/an-ipad-pro-pro-mode-may-sound-nice-but-it-all-depends-5262aa882f23"
publisher : "medium"
date : "2022.05.12"
tags : ["waiting","iPadpro"]
type: "Extracts"
---
每个字段的含义:
author:文章作者。link:原文 URL 地址。publisher:原文发行机构。date:文章摘录日期。tags:设置笔记的标签waiting:代表文章摘录中。Done:代表文章摘录完成。type:笔记类型, "Extracts" 代表这是一篇「摘录笔记」。
可以看到所有「摘录笔记」都会设置 type:"Extracts" ,同时添加 #waiting 标签,代表「摘录笔记还在编辑中」,所以如果想要筛选出「所有未完成的摘录笔记」,查询条件应该是「所有包含 #waiting 标签的且元数据中 type: 值 为"Extracts" 的笔记」,这里依然使用 dataviewjs 语法如下:

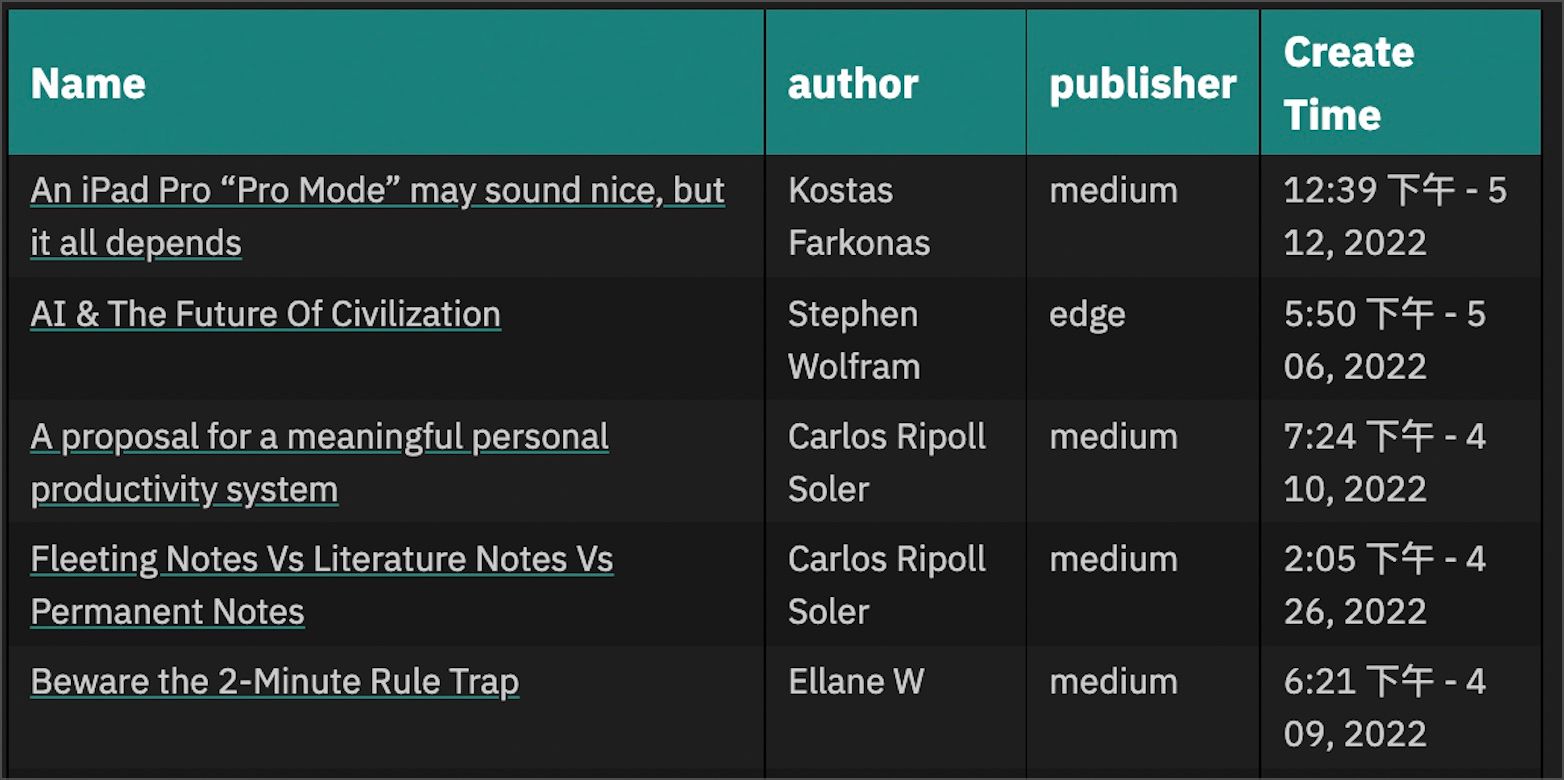
dv.table:函数名,此函数会在笔记中输出一张表格。["Name","author","publisher","Create Time"]:函数dv.table的第一个参数,指定表格的字段名,分别是笔记标题(双向链接的形式)、文章作者、发布平台、创建笔记的时间。dv.pages("#waiting"):这部分相当于获得了一个笔记数组变量,其内容是所有包含标签#waiting的笔记。.where:函数名,它等同于dv.pages("#waiting").where,即在上一步dv.pages("#waiting")得到的「数组变量」基础上,再按照指定的「条件」进行查询,其条件就是函数的参数:.where(b=> b.type=="Extracts")。b=>:这里的b可以用任何字母代替,实际上b所指代的就是pages中的「每一篇笔记」。b.type=="Extracts":指定了.where的查询条件,其中b.type代表笔记「元数据」中type的值,这里的意思是查询条件为「笔记的元数据中type值等于Extracts」。- 综合看
.where(b=> b.type=="Extracts")就相当于dv.pages("#waiting").where(b=> b.type=="Extracts"),其意思就是在所有包含标签#waiting的笔记中,查询所有「元数据」中type等于Extracts的笔记。 .sort:函数名,它等同于dv.pages("#waiting").where(b=> b.type=="Extracts").sort(),即将上一步查询后后得到的「数组变量」按照一定规则进行排序。b=>:这里的b可以用任何字母代替,它依然代表「数组变量」中的「每一篇笔记」。b.file.mtime:它的意思是「笔记的最后修改时间」,这里代表使用「笔记的最后修改时间」进行排序。这里依然用到了dataview中的「隐式字段」。desc:指定「排序规则」为「倒排」或者「降序」。具体到当前就是指按照file.mtime「笔记的最后修改时间」倒排,最新的修改的笔记在表格最上边。- 综合看
.sort(b=> b.file.mtime,"desc")就相当于dv.pages("#waiting").where(b=> b.type=="Extracts").sort(b=> b.file.mtime,"desc"),其意思就是在所有包含标签#waiting的笔记中,查询所有「元数据」中type等于Extracts的笔记,并且按照「笔记的最后修改时间」b.file.mtime倒序排序。 .map:函数名,它等同于dv.pages("#waiting").where(b=> b.type=="Extracts").sort(b=> b.file.mtime,"desc").map(),即对上一步「排序后」的所有笔记进行「重组」,只返回每个笔记的「指定字段」(见下文)。b=>:这里的b可以用任何字母代替,它依然代表pages中的「每一篇笔记」。b.file.link:它的意思是「指向笔记的链接」,即返回「排序后」的「数组变量」中的每一篇笔记的「双向链接」值(类似[[笔记1]])。它对应的就是表格中的第一个字段Name。b.author:它的意思是笔记的「元数据」中的author字段值(作者),即返回「排序后」的每一篇笔记的「元数据」中的author字段的值。它对应的事表格中的第二个字段author。b.publisher:它的意思是笔记的「元数据」中的publisher字段值(发行机构),即返回「排序后」的每一篇笔记的「元数据」中publisher字段的值。它对应的事表格中的第三个字段publisher。b.file.ctime:它的意思是笔记的「创建时间」,即返回「排序后」的每一篇笔记的「创建时间」。它对应的事表格中的第四个字段Create Time。- 综合看,
.map(b => [b.file.link,b.author,b.publisher,b.file.ctime])的意思就是将上一步「排序后」的「数组变量」进行「重组输出」并与dv.table指定的四个字段对应,即返回笔记的双向链接、原文的作者、原文发行机构、笔记的创建时间。
最后我们整体再看一下完整的语法:

它分为五部分:
- 第一部分,执行函数
dv.table,并设定函数「输出表格」的字段。 - 第二部分,得到
dv.pages数组变量,其值等于所有标签为#waiting的笔记。 - 第三部分,按照条件
b.type=="Extracts",进一步查询dv.pages数组变量中笔记的「元数据」中的type值等于Extracts的笔记。 - 第四部分,按照「笔记的最后修改时间」
b.file.mtime进行「倒序」。 - 第五部分,重组
dv.pages数组变量,只输出指定的四个字段b.file.link,b.author,b.publisher,b.file.ctime。
归档笔记
归档笔记列表展示的是部分已经「归档」不再看的笔记,样式如下:
这个规则很简单,就是所有标签为 Done 的笔记(使用中如果想归档一篇笔记,设置 #Done 标签即可),代码如下:
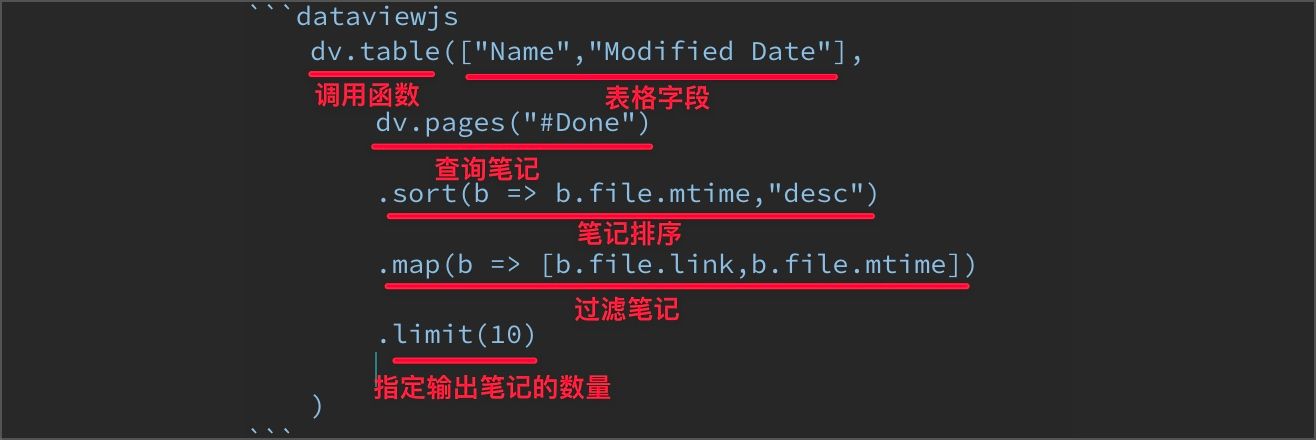
dv.table:函数名,此函数会在笔记中输出一个表格。["Name","Modified Date"]:指定表格的字段名,分别是笔记的「双向链接」和笔记的「修改时间」。dv.pages("#Done"):查询所有包含标签#Done的笔记。.sort(b => b.file.mtime,"desc"):排序函数,将上一步获得的「数组变量」按照「笔记最后修改时间」b.file.mtime进行「倒排」。.map(b => [b.file.link,b.file.mtime]):重组函数,将上一步排序后的「数组变量」重组,只返回笔记的「双向链接」和笔记的「最后修改时间」。.limit(10):限制返回行数,指定「排序」并「重组」后的「数组变量」返回的行数,这里限制只返回 10 条数据。
整个语法分为五部分:
- 第一部分,执行函数
dv.table,并设定函数「输出表格」的字段。 - 第二部分,得到
dv.pages数组变量,其值等于所有标签为#Done的笔记。 - 第三部分,按照「笔记的修改时间」
b.file.mtime进行「倒序」。 - 第四部分,重组排序后的
dv.pages数组变量,只输出指定的两个字段b.file.link,b.file.mtime。 - 第五部分,设置数组变量的返回值数量为 10 条。
HomePage-Right
再看右侧它包含如下内容:
- Daily
- 最近修改
- 稍后读
- 闪念胶囊 Todo
- 其他未完成任务
Daily
这个区域展示最新的五条「间歇式日记」,展现样式如下:

注意现在输出的是一个「列表」不再是表格。关于「最新的五条间歇式日记」查询方法很简单,就是 Daily 目录下所有笔记按照「文件修改时间」倒排,并取 5条数据,代码如下:

注意:这次有些不同,代码并没有放在 dataviewjs 下,而是放在了 dataview 下边,这说明这段代码并没有使用 JavaScript 语法,而是 Dataview 的语法。
LIST:关键字,指的是查询一段内容,并按照列表进行展示(注意列表并不是表格,他没有表头等信息)。From "Daily":指定「查询源」,例如本例中From "Daily",即「查询名为Daily的文件夹下的所有笔记」。sort:排序关键字file.mtime:指定排序字段,本例中指的是按照「文件的最后修改时间」排序。desc:排序关键字,desc 指的是「倒排」,本例中指的是按照「文件最后修改时间倒排」,即最新修改的在最上边。limit (5):指定返回列表的数量,本例中指的是在所有符合条件的笔记中(文件夹Daily下所有按照「最后修改时间倒排」后的笔记列表)只返回5条。- 综合看,整个语句的意思是「查询
Daily文件夹下所有笔记,只返回最新修改的5篇笔记」。
最近修改
这个区域展示最近10天内修改的五篇笔记,展示样式如下:

这次样式依然是一个「列表」而不是表格,查询条件是「笔记的修改时间在10天内」,代码如下:

LIST:关键字,指的是查询一段内容,并按照列表进行展示。WHERE:关键字,代表其后的内容就是查询条件。这次没有From关键字,代表这次是从「所有笔记」中查询。file.mtime >= date(today) - dur(10 day):此段语法指明了「文件最后修改时间」要在10天内(注意代码中的>=)。sort:排序关键字file.mtime:指定排序字段,本例中指的是按照「文件的最后修改时间」排序。desc:排序关键字,desc 指的是「倒排」,本例中指的是按照「文件最后修改时间倒排」,最新修改的在最上边。limit (5):指定返回列表的数量。- 综合看,整个语句的意思是「查询所有最后修改时间在10天内的笔记,并且只返回5条」。
稍后读
在 Obsidian 中管理 Todo 是非常方便的,在每行笔记的开头添加 - [ ] ,也可以通过快捷键 CMD+Enter Obsidian 会自动在行首添加 - [ ],如果完成 Todo 处理也很简单,在「预览状态」下打钩即可如图:

在 Obsidian 中通过 Todo 管理「稍后读」,任何一篇笔记中如果想将一篇文章进行「稍后阅读」,直接创建一条 Todo,并添加 #稍后读 标签即可,如图:
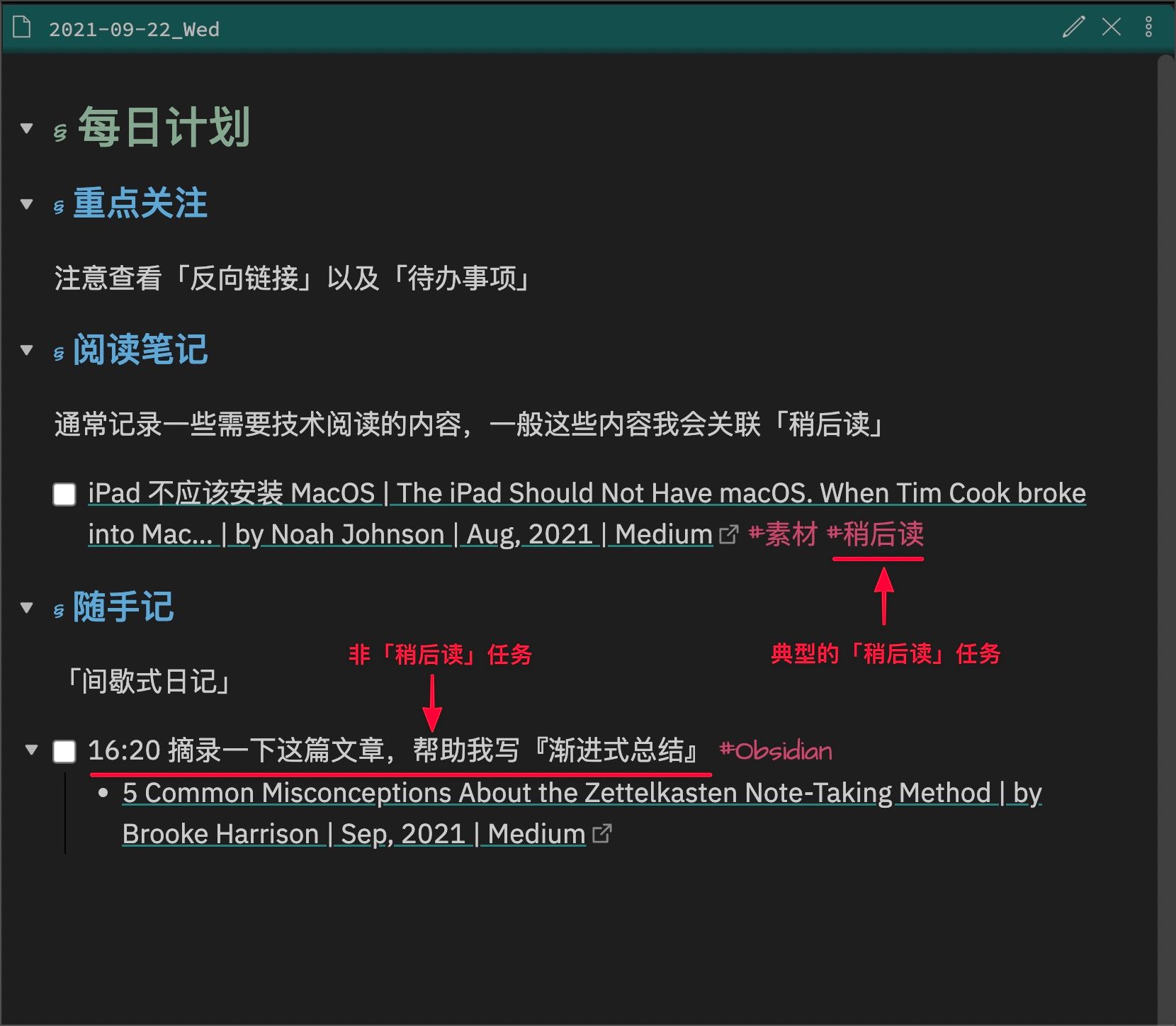
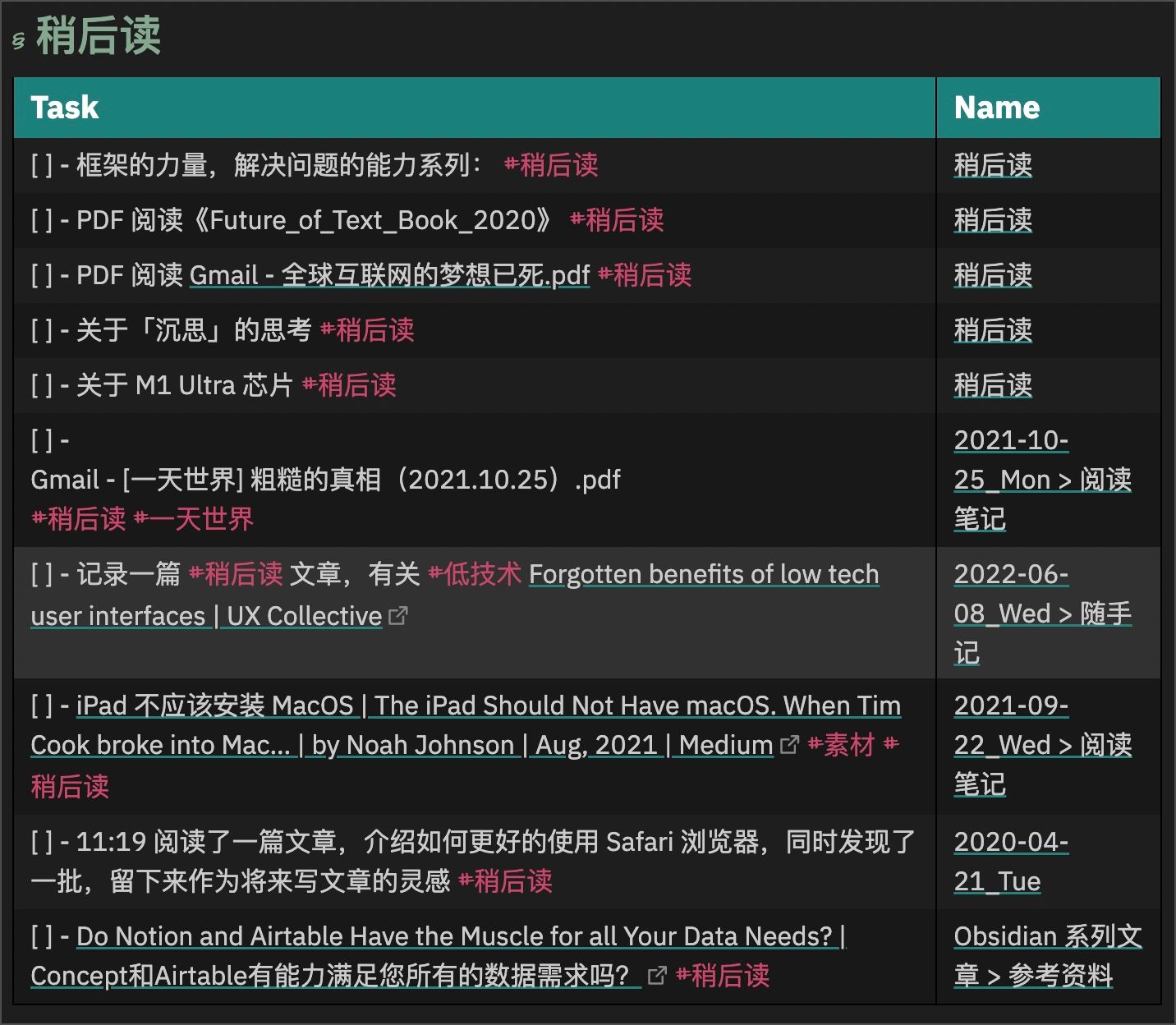
所以在 HomePage 中「稍后读」区域展示的是「所有设置了#稍后读 标签的 Todo」,样式如下:
在继续介绍代码之前,先了解一下 Dataview 对 Todo 的支持。
Dataview 对 Obsidian 中的任务(TODO)支持非常好,它可以准确识别任务是否完成(已完成的都会打钩),并且支持「代码级」的筛选,例如使用如下语句可以在所有笔记中筛选出「未完成的任务」:
dv.pages().file.tasks.where(t => !t.completed)
可以看到 dataviewjs 中针对 Task 做了代码级支持,每个笔记都可以通过 file.tasks (前文中提到的「隐式字段」)找到当前笔记的「所有任务」,并且支持 where 条件过滤,变量 t.completed 代表任务的「完成状态」,true 代表「已完成」相反就是「未完成」。所以如果想要在所有笔记中查询所有「已完成的任务」语句如下:dv.pages().file.tasks.where(t => t.completed)
结合 Obsidian 中管理「稍后读」的方式以及 Dataview 对 Todo 的支持,筛选所有「未完成的稍后读任务」就相当于两个查询条件:
- 条件1:在所有包含标签
#稍后读的笔记中查询,语句:dv.pages("#稍后读")。 - 条件2:循环每一篇笔记,找到所有未完成的任务,语句:
file.tasks.where(t => !t.completed)。
查询条件并没完,大家想一下,一篇包含 #稍后读 的笔记中,所有的「未完成 Todo」就一定是「稍后读」任务吗?它也可以是这篇笔记的「其他任务」,例如下图中的第二个 Todo:

所以我们还要增加一个条件3:任务表标题中包含 #稍后读 关键字。
综上所述语法如下:
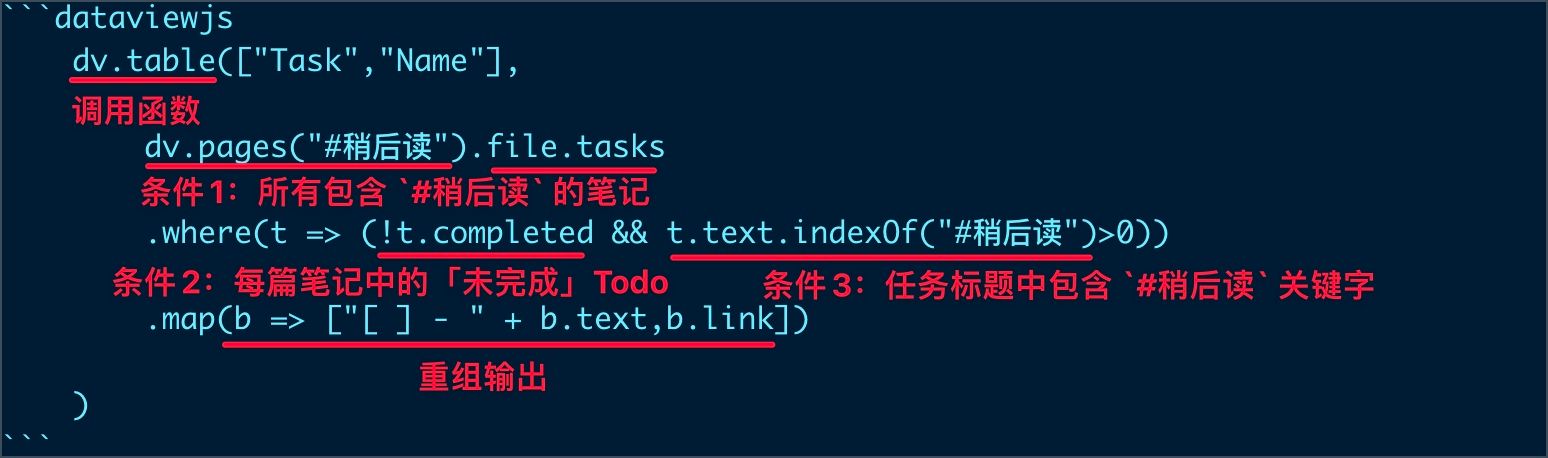
dv.table:函数名,此函数会在笔记中输出一个表格。["Task","Name"]:指定表格的字段名,分别是任务标题和笔记的「双向链接」。dv.pages("#稍后读"):查询所有包含标签#稍后读的笔记。file.tasks:这是个新的语法,它返回当前笔记的「所有任务」(也就是 Todo),跟在dv.pages("#稍后读")后,代表我们将得到一个「数组变量」,其中每一条就是一条「任务」,通俗的说这将得到「所有包含#稍后读的笔记中的所有任务」。.where:函数名,它等同于dv.pages("#稍后读")file.tasks.where,即在上一步得到的「所有包含#稍后读的笔记中的所有任务」基础上,再按照指定的「条件」进行查询。t=>:这里的t可以用任何字母代替,它代指上文中「所有包含#稍后读的笔记中的所有任务」中的「每一条任务」。!t.completed:第一个查询条件也成为「表达式」,!t.completed代表查询条件为「未完成的任务」,我们拆开看t.completed属于JavaScript的简写语法,写全了就是t.completed == true,在语句前加上!,代表对t.completed == true「取反」,写全了相当于t.completed == false,即任务完成状态是「未完成」。&&:关键字「逻辑与」,代表&&左边!t.completed和右边t.text.indexOf("#稍后读")>0两个查询条件必须同时满足(即两个表达式得到 true),与之相反的还有||「逻辑或」,即左边和右边满足任意一边即可(即两个表达式任意一个得到 true)。t.text.indexOf("#稍后读")>0:第二个查询条件,它代表查询条件为「任务标题包含关键字#稍后读」,其中t.text代表「任务详情」,.indexOf("#稍后读")>0就是典型的JavaScript语法,代表「任务详情中包含关键字#稍后读。.map(b => ["[ ] - " + b.text,b.link]):重组函数,将上一步符合条件的笔记中的任务重组,分为两部分:- 有一点特别注意,此处是按照「每条任务」进行输出,而不是之前的「每篇笔记」,原因是这些语句都在
.file.tasks之后。 "[ ] - " + b.text:在任务标题前加上[ ] -这样输出的时候样式看起来更像一条任务。此表达式对应表格的第一个字段。b.link:笔记的链接,此表达式对应表格的第二个字段。- 综合看,语句查询所有包含
#稍后读标签的笔记,并过滤笔记中的「所有任务」,只输出状态是「未完成」且「任务标题包含稍后读关键字」的 Todo。最后输出到表格中,第一列展示任务的标题,第二列展示任务所在的笔记的「双向链接」。
闪念胶囊
闪念胶囊和「稍后读」类似,都是查询所有包含标签 #闪念胶囊 的笔记,并过滤笔记中的所有「未完成」 Todo(同时确保 Todo 标题中包含 #闪念胶囊 关键字),语法如下:

此段代码除了 #闪念胶囊 之外,其他全部和「稍后读」一样,具体含义大家自己对照即可,这里不再重复。
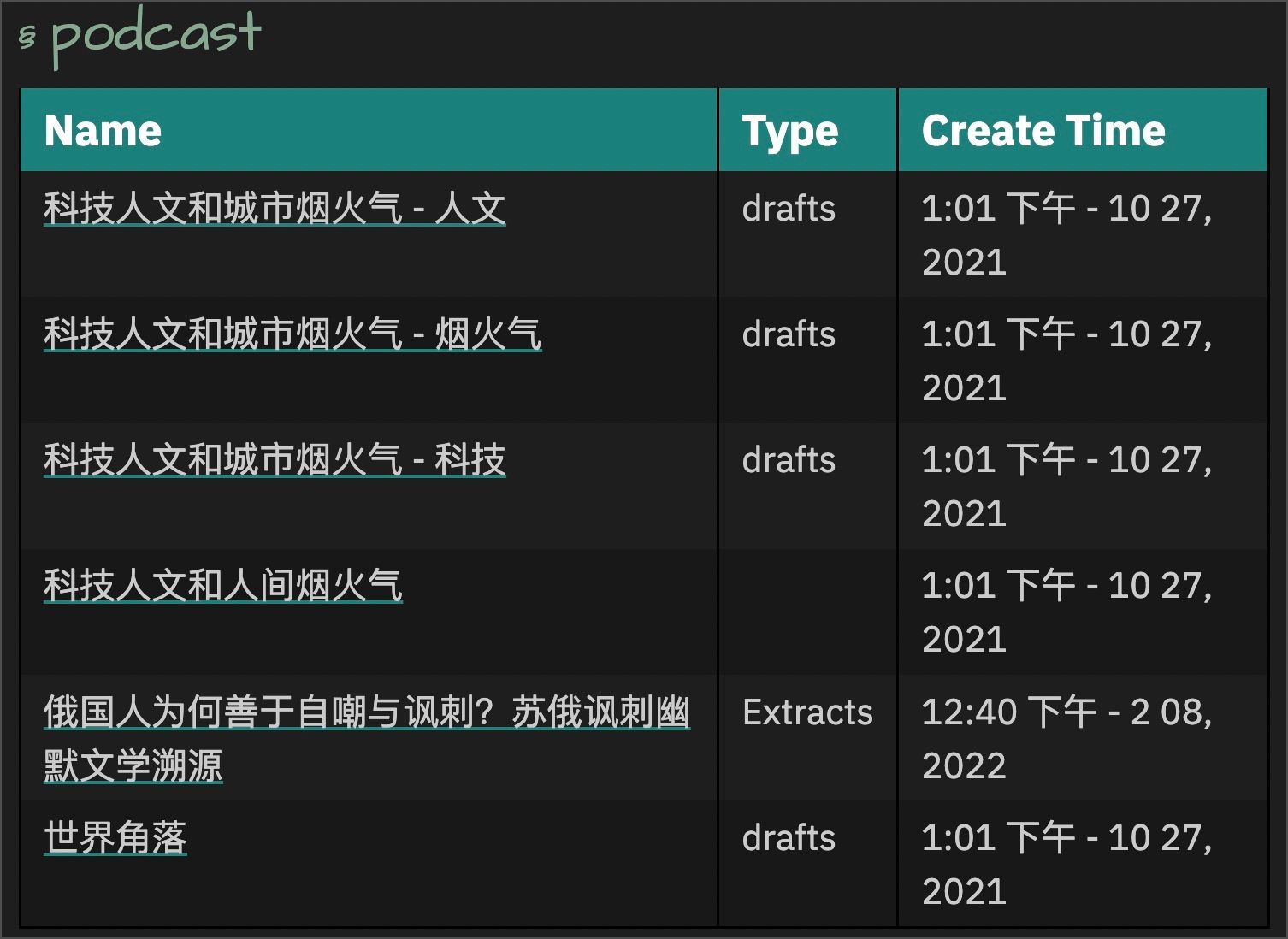
PodCast
首先看一下 PodCast 笔记的「元数据」组成:

所以,PodCast 区域展示的是所有包含 #PodCast 和 #waiting 的笔记,语法上跟上文中的「未完成的 Blog」一样,具体含义大家可以自己对照,这里不再重复。
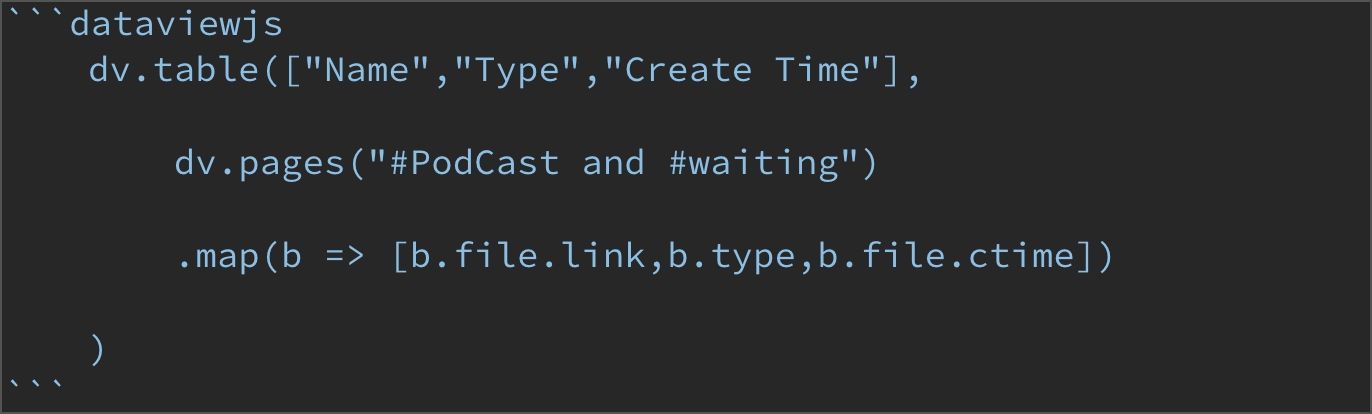
最终展示效果:
课后作业
到这里 HomePage-Right 还有最后一段「其他未完成任务」,接下来我不想直接给出相关代码,而是给大家留一个「课后作业」,欢迎有动手能力和探索欲的读者亲自上手,借助之前的代码看能否实现「其他未完成的任务」的编码,相关提示如下:
- 其他任务指的是除了「闪念胶囊」和「稍后读」之外的 Todo,可以使用「不包含某标签」的查询语句。
- 代码上可以参考「未完成的 Blog」部分。
**「其他未完成任务」**的展示样式如图:

最后
回顾一下,文章开头提出了使用 Obsidian 进行「知识管理」一段时间后面临的两个问题:
- 问题1:各种笔记种「线索太多」容易遗忘正在做的事情,例如未完成的摘要、写一半的博客、定期整理的「闪念胶囊」等。
- 问题2:各种相关 Todo 散落在笔记中,记不清也找不全,导致许多任务无法完成或推进。
本文介绍了 Obsidian 第三方插件 Dataview ,并介绍了如何通过「编码」实现「自动化 HomePage」解决问题,相关代码可以** 在 Github 查看 **。大家下载保存后,简单修改其中的一些「关键字」,即可打造属于自己的「自动化 HomePage」,欢迎尝试。
当然,Dataview 的功能也远不止文中介绍这些,本篇还是想通过「示例」的方式抛砖引玉,带着大家逐步掌握 Dataview 的用法,各位读者如果在阅读本文后,有新的玩法或建议,可以在评论区讨论提问,我会尽量回复大家,感谢阅读。
「玩转 Obsidian」系列会持续更新「如何使用 Obsidian 进行知识管理」,对此系列感兴趣可以在以下渠道找到相关文章:
玩转 Obsidian 系列目前包括文章:
- 《玩转 Obsidian 01:用 Obsidian 打造「知识循环」利器》
- 《玩转 Obsidian 02:基础设置篇》
- 《玩转 Obsidian 03:如何记录「间歇式日记」》
- 《玩转 Obsidian 04:为什么推荐使用 Obsidian 做知识管理》
- 《玩转 Obsidian 05:如何进行阅读及摘要》
- 《玩转 Obsidian 06:如何用 Obsidian 进行渐进式总结》
- 《玩转 Obsidian 07 :自动化「间歇式日记」》
- 《玩转 Obsidian 08:利用 Dataview 打造自动化 HomePage》
可以在 Twitter、Telegram 等渠道关注我,获取更多有意思的讯息。
即「卡片笔记法」在《玩转 Obsidian 01:打造知识循环利器 - 少数派》中有详细介绍。 ↩
即我们管理笔记不应该被标签或文件夹限制住(存放在哪里),更应该关注笔记内容本身。笔记应该具备「原子性」,每个原子有自己的特性,并可以随时组成更强大的元素或分子化合物。更多概述在《玩转 Obsidian 04:为什么推荐使用 Obsidian 做知识管理》 ↩
指的是以「写作」为唯一目的的「知识管理」方式,即在「写作」的过程中经历阅读/记录/整理和输出。在《玩转 Obsidian 01:打造知识循环利器 - 少数派》中有详细介绍。 ↩


